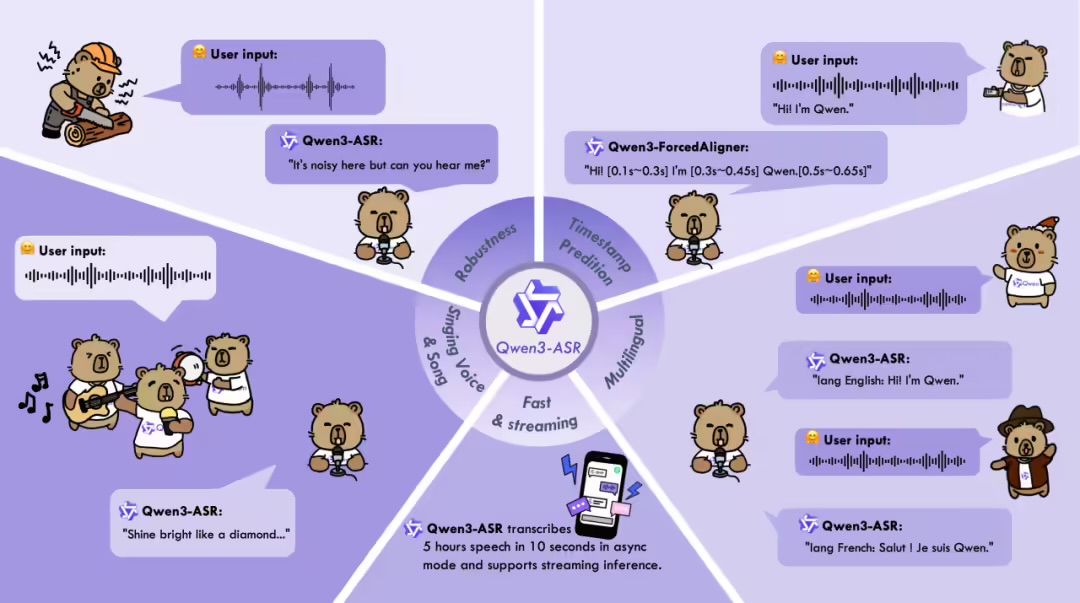

29 януари — Екипът на Qwen на Alibaba официално отвори серията модели Qwen3-ASR, мощна гама от модели за разпознаване на реч, разработени от семейството Qwen. Изданието включва два пълнофункционални ASR модела – Qwen3-ASR-1.7B и Qwen3-ASR-0.6B – както и иновативен модел за принудително подравняване на речта, Qwen3-ForcedAligner-0.6B. Заедно серията Qwen3-ASR поддържа разпознаване на реч и езикова идентификация на 52 езика и диалекта.
Според Alibaba, Qwen3-ASR използва новоразработен AuT предварително обучен говорен енкодер, комбиниран със силната мултимодална основа на Qwen3-Omni, което позволява много точно и стабилно разпознаване на реч. Моделът 1.7B постига най-съвременна (SOTA) производителност в множество сценарии, включително мандарин китайски, английски, реч с китайски акцент и разпознаване на глас при пеене, като същевременно демонстрира силна устойчивост на сложен текст и среди с висок шум.
Моделът 0.6B постига баланс между производителност и ефективност. Като поддържа висока точност на разпознаване, той поддържа 128 едновременни асинхронни изводи с пропускателна способност до 2000×, способни да обработват повече от пет часа аудио само за 10 секунди.
Qwen3-ForcedAligner-0.6B е модел за предсказване на времево клеймо, базиран на неавторегресивен (NAR) извод на голям езиков модел, поддържащ гъвкаво и прецизно принудително подравняване в 11 езика на произволни позиции. Неговата точност на клеймото за време надминава традиционните модели като WhisperX и Nemo-Forced-Aligner, постигайки ефективен коефициент в реално време (RTF) от 0,0089 при едновременен извод.
Екипът на Qwen заяви, че предлагането на серията Qwen3-ASR с отворен код има за цел да ускори изследванията и иновациите в разпознаването и разбирането на реч. Архитектурите на модела, теглата и изчерпателната, удобна за потребителя рамка за изводи ще бъдат пуснати като част от пакета с отворен код.
Източник: ITHome
Source link
Like this:
Like Loading…
Нашия източник е Българо-Китайска Търговско-промишлена палaта